
项目背景:
1、现在很多平台客户关系管理系统都是使用传统的CRM,所有的信息全靠手工录入,用户寻找上下游企业或者信息只能靠手工去查找并且标注。
2、大数据时代的到来,人工智能,云计算,先进的分析,用机器去替代人工的部分,从 2016 年趋势看,机器学习和人工智能 (AI) 将在未来几年内将会彻底改变 CRM。
因此我们对CRM进行了改造,主要有如下部分:
1、企业信息、商品信息来自互联网,机器学习去自动统计分析并且分类。
2、用户录入的商品信息和新从互联网爬来的商品信息全部通过机器学习计算的模型去分类。
3、机器学习自动计算企业和供求信息上下游。
4、机器学习每隔一段时间自动去优化计算模型。
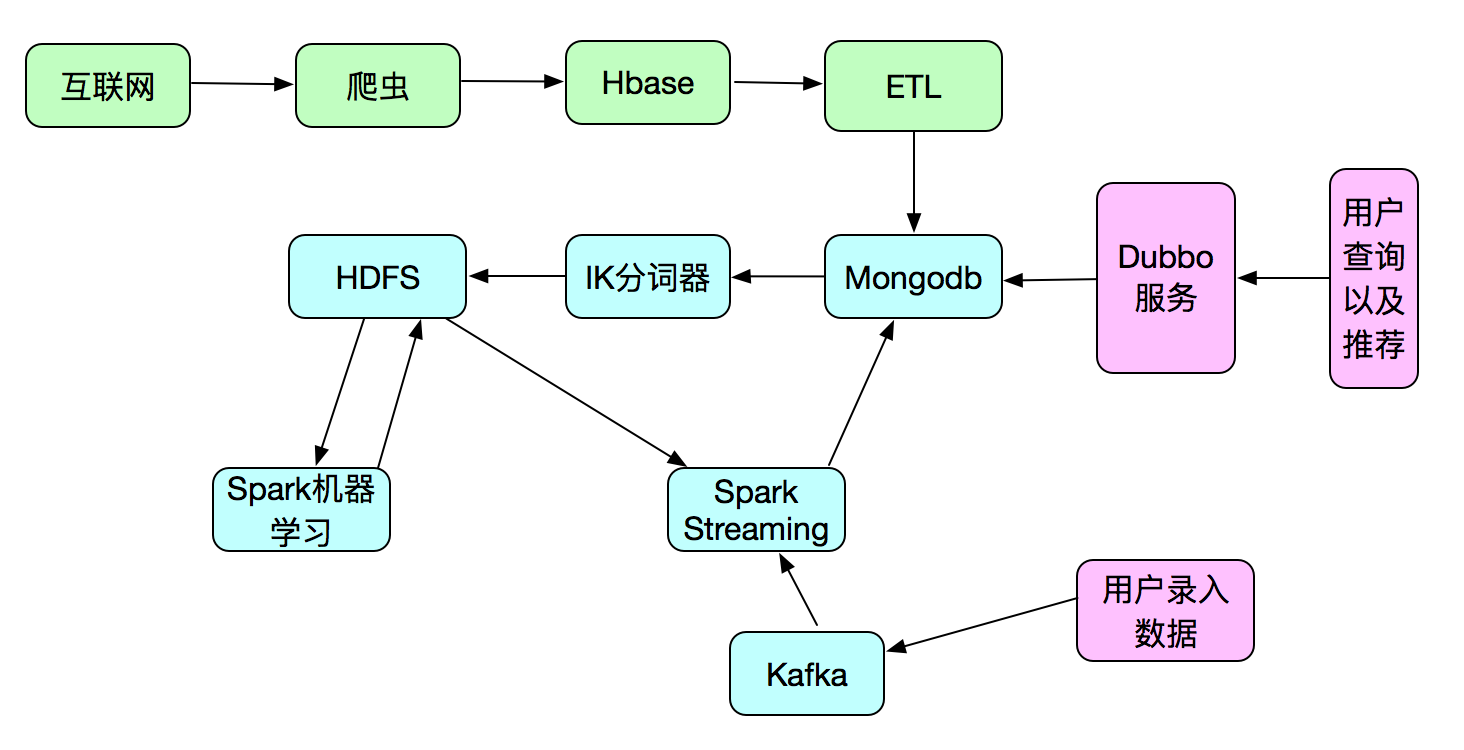
根据图识,项目将分为三个部分。整个项目基本思路是如何通过爬虫爬取大量数据放到Hbase,然后通过ETL工具初步转化筛选将数据存到mongodb,抽取mongodb的数据进行清洗处理算出模型放到hdfs。后续进来数据通过模型运算出数据的类型。项目系统主要包括前端+后端+机器学习,前端采用React Native,Native,后端采用Dubbo+Spring+java,机器学习采用Spark进行实现,本项目机器学习-spark代码运行在mesos上。
本课程我们只针对以上图示的浅蓝色部分内容(即与机器学习相关的内容),通过用真实的智能客户项目系统作为案例(案例附带源码,可以直接做二次开发),主要根据项目实例穿讲机器学习以及相关知识,包括有:数据提取,数据清洗以及分词,数据特征值提取、机器学习模型计算、数据分类等等,进行详细讲解。
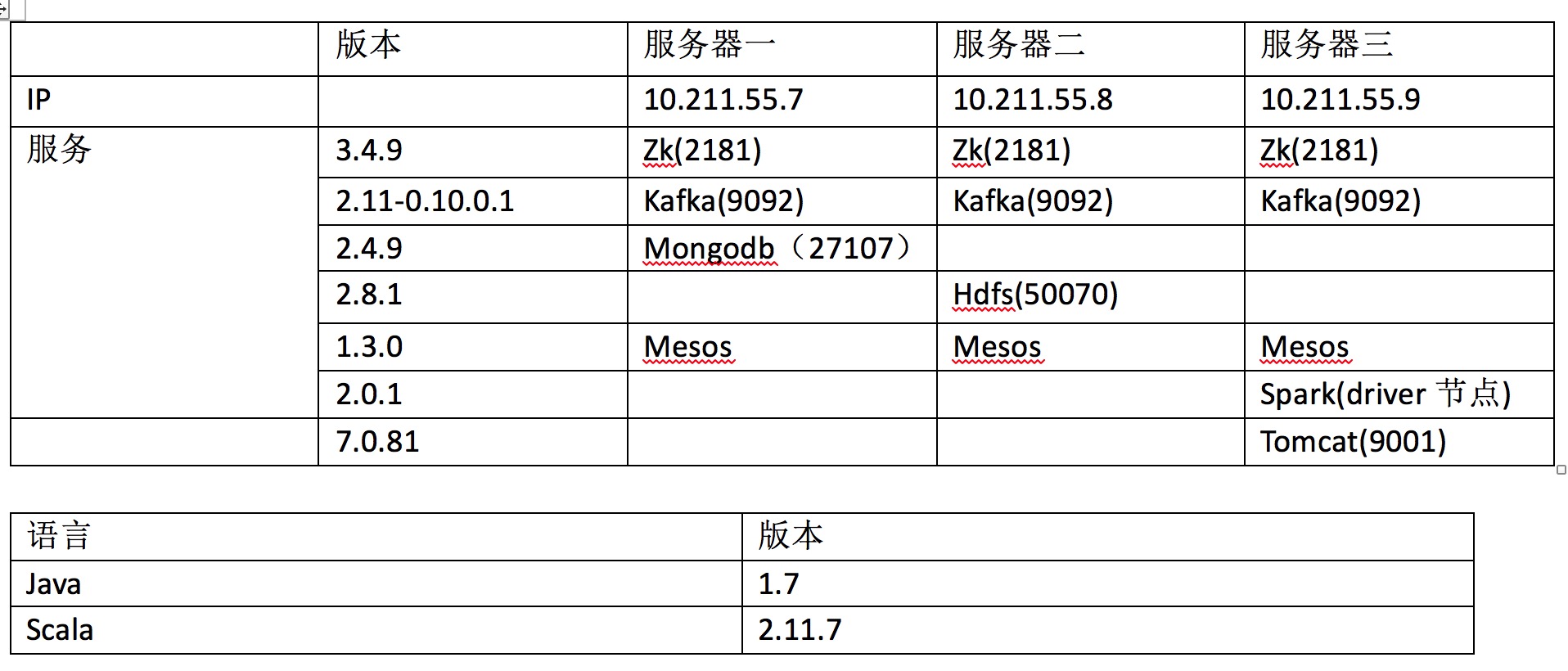
本课程所需掌握的技术:java、scala、IK、Hdfs、Spark ml、Spark Streaming、Spark SQL、Kafka、Zookeeper、Mongodb、Spring-Data-Mongodb,由于每个技术需要掌握的程度不一样,对于我们用到的一些开源技术,课程中将会是简单介绍如何使用,不会着重讲解。课程重点讲解spark ml、spark Streaming,以及如何使用这些技术进行项目的实战,贯穿项目系统并且最后串联所有技术。spark基于2.0.1版本讲解

- 官方微信

 粤公网安备 44010602005928号
粤公网安备 44010602005928号